Goal
This project is primarily educational, aiming to understand various ensemble learning algorithms by implementing them from scratch using numpy for array processing and custom datasets.
Overview
This project includes implementations of custom random forest classifiers and regressors, as well as a gradient boosted decision tree regressor.
Main Python Files
- dataPrep.py: Contains functions for data preparation and one-hot encoding
- decisionTreeClassifier.py: Implements a decision tree classifier
- decisionTreeRegressor.py: Implements a decision tree regressor
- randomForestClassifier.py: Implements a custom random forest classifier
- randomForestClassifierPar.py: Updated randomForestClassifier.py to implemented with multiprocessing for performance gain.
- randomForestRegressor.py: Implements a custom random forest regressor
- gradientBoostedRegressor.py: Implements a gradient boosted decision tree regressor
- runRandomForest.py: Functions to run random forest on various datasets
Included CSV Files
- Wisconsin_breast_prognostic.csv: Dataset for Wisconsin Breast Prognostic analysis
- pima-indians-diabetes.csv: Dataset for Pima Indians Diabetes analysis
- output_May-06-2024_cleaned.csv: Car listing data from "used_car_price_visualization" repository
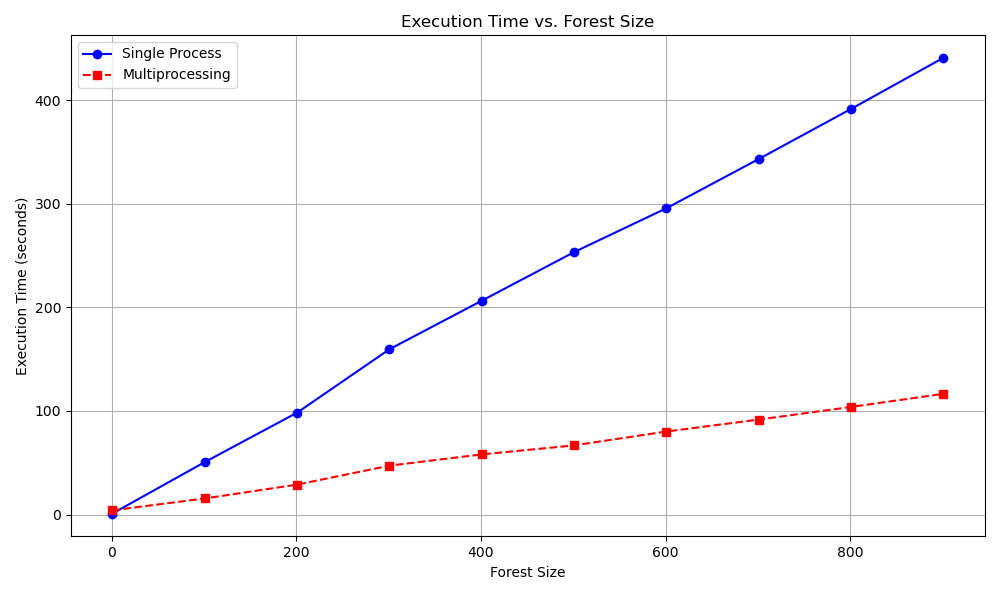
Example Results
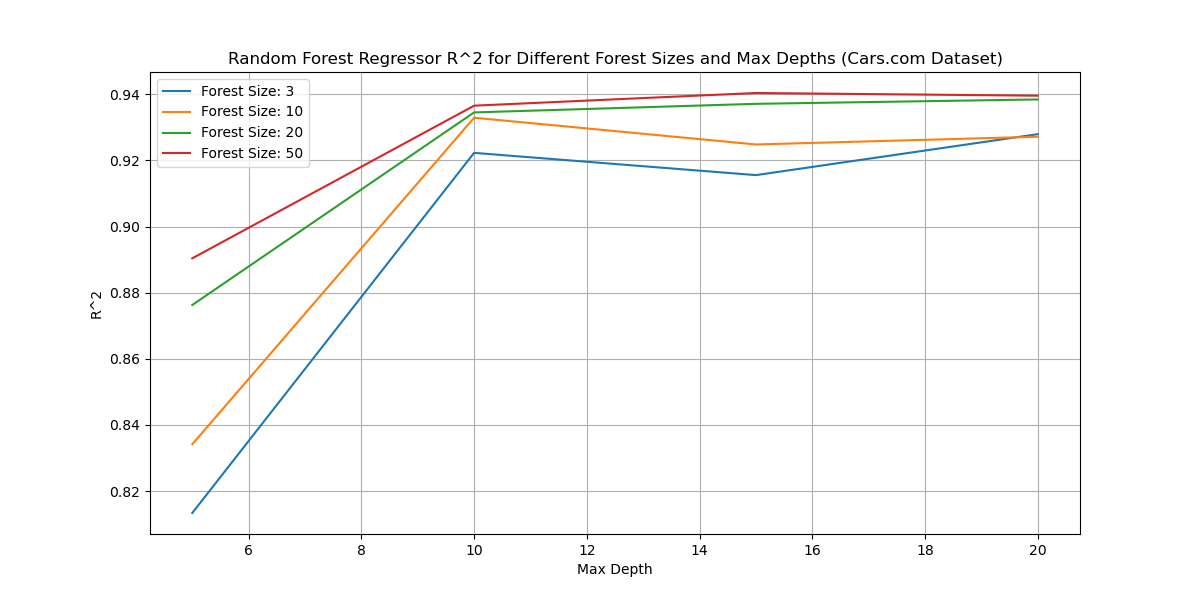
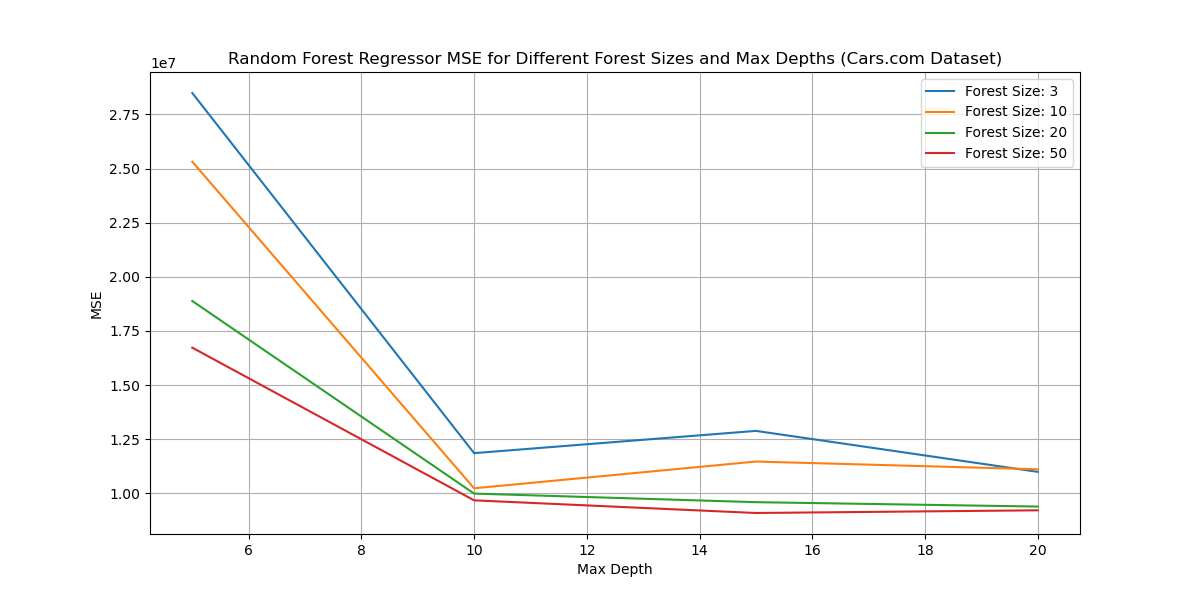
Multiprocessing Performance Gain
randomForestClassifierPar vs randomForestClassifier
Usage Example
This run function in gradientBoostedRegressor.py demonstrates how to prepare data, train the model, and evaluate its performance:
def run():
"""
Runs Gradient Boosted Decision Trees on the given dataset.
"""
# Source file location
file_orig = "data/carsDotCom.csv"
# Prepare and format data
df, file_loc = dp.DataPrep.prepare_data(file_orig, label_col_index=4, cols_to_encode=[1,2,3])
# Initialize GBDT object
gbdtDiab = gradientBoostedRegressor(file_loc, num_trees=10, random_seed=0, max_depth=3)
# Train GBDT model
gbdtDiab.fit(stats=True)
# Predict target values
predictions = gbdtDiab.predict()
# Get stats
stats = gbdtDiab.get_stats(predictions)
print(stats)
if __name__ == "__main__":
run()
dataPrep.py
Class: DataPrep
- one_hot_encode(df, cols): One-hot encodes non-numerical columns in a DataFrame
- write_data(df, csv_file): Writes the DataFrame to a CSV file
- prepare_data(csv_file, label_col_index, cols_to_encode=[], write_to_csv=True): Prepares data by loading a CSV file, one-hot encoding non-numerical columns, and optionally writing prepared data to a new CSV file
decisionTreeClassifier.py
Classes: Utility, DecisionTree, DecisionTreeWithInfoGain
- Utility: Utility class for computing entropy, partitioning classes, and calculating information gain
- DecisionTree: Decision tree for classification tasks
- DecisionTreeWithInfoGain: Extends DecisionTree to use information gain for splitting
decisionTreeRegressor.py
Classes: Utility, DecisionTreeRegressor
- Utility: Utility class for computing variance, partitioning classes, and calculating information gain
- DecisionTreeRegressor: Decision tree for regression tasks
randomForestClassifier.py | randomForestClassifierPar.py
Classes: RandomForest, RandomForestWithInfoGain, runRandomForest
- RandomForest: Custom random forest classifier with bootstrapping and voting mechanisms
- RandomForestWithInfoGain: Extends RandomForest to use information gain for splitting
- runRandomForest: Functions to run the random forest classifier
randomForestRegressor.py
Classes: RandomForest, runRandomForest
- RandomForest: Custom random forest regressor with bootstrapping and aggregation mechanisms
- runRandomForest: Functions to run the random forest regressor
gradientBoostedRegressor.py
Class: gradientBoostedRegressor
- gradientBoostedRegressor: Gradient boosted decision tree regressor for regression tasks
- Attributes: random_seed, num_trees, max_depth, X, y, XX, numerical_cols
- Methods: __init__, reset, fit, predict, get_stats
- Example Usage: run function to prepare data, train the model, and evaluate performance
runRandomForest.py
Functions to run custom random forest classifier and regressor on various datasets.